
Concepto de un sistema de información
Es un conjunto de elementos orientados al tratamiento y administración de datos e información, están organizados y listos para su uso posterior, estos son generados para cubrir una necesidad u objetivo.
Un sistema de información se puede definir técnicamente como un conjunto de componentes relacionados que recolectan (o recuperan), procesan, almacenan y distribuyen información para apoyar la toma de decisiones y el control en una organización.
Un Sistema de Información, es aquél que permite recopilar, administrar y manipular un conjunto de datos que conforman la información necesaria para que los estamentos ejecutivos de una organización puedan realizar una toma de decisiones.
Clases de Sistemas de Información
Debido a que el principal uso que se da a los SI es el de optimizar el desarrollo de las actividades de una organización con el fin de ser más productivos y obtener ventajas competitivas, en primer término, se puede clasificar a los sistemas de información en:
1- Sistemas Competitivos
2- Sistemas Cooperativos
3- Sistemas que modifican el estilo de operación del negocio
Esta clasificación es muy genérica, y en la práctica no obedece a una diferenciación real de sistemas de información reales, ya que en la práctica podríamos encontrar alguno que cumpla varias (dos o las tres) de las características anteriores. En los subapartados siguientes se hacen unas clasificaciones más concretas (y reales) de sistemas de información
Que es un Dato
En programación, un dato es la expresión general que describe las características de las entidades sobre las cuales opera un algoritmo.
En Estructura de datos, es la parte mínima de la información
Que es información
Es un conjunto organizado de Datos procesados, que constituyen un mensaje que cambia el estado de conocimiento del sujeto o sistema que recibe dicho mensaje.
Origen Y Concepto De Bases De Datos
Las Bases de Datos son programas que administran información y hacen más ordenada la información, aparte de hacerla fácil de buscar, Desde tiempos remotos los datos han sido registrados por el hombre en algún tipo de soporte (piedra, madera, , cintas magnéticas, discos, etc.) debido a su importancia
Sus características pueden ser ventajosas o desventajosas: pueden ayudarnos para almacenar, organizar, recuperar, comunicar y manejar información en formas que serían imposibles sin los computadores, pero también nos afecta de alguna manera ya que existen enormes cantidades de información en bases de datos de las que no se tiene control del acceso
Las bases de Datos tienen muchos usos: nos facilitan el almacenamiento de grandes cantidades de información; permiten la recuperación rápida y flexible de información, con ellas se puede organizar y reorganizar la información, así como imprimirla o distribuirla en formas diversas.
Concepto Y Origen De Los Sistema Gestor Base De Datos Relacional
Un sistema de gestión de bases de datos (SGBD) es un conjunto de programas que permiten el almacenamiento, modificación y extracción de la información en una base de datos, además de proporcionar herramientas para añadir, borrar, modificar y analizar los datos. Los usuarios pueden acceder a la información usando herramientas específicas de interrogación y de generación de informes, o bien mediante aplicaciones al efecto Los SGBD también proporcionan métodos para mantener la integridad de los datos, para administrar el acceso de usuarios a los datos y para recuperar la información si el sistema se corrompe. Permite presentar la información de la base de datos en variados formatos. La mayoría de los SGBD incluyen un generador de informes. También puede incluir un módulo gráfico que permita presentar la información con gráficos y tablas.
Hay muchos tipos de SGBD distintos según manejen los datos y muchos tamaños distintos según funcionen sobre ordenadores personales y con poca memoria a grandes sistemas que funcionan en mainframes con sistemas de almacenamiento especiales.
Generalmente se accede a los datos mediante lenguajes de interrogación, lenguajes de alto nivel que simplifican la tarea de construir las aplicaciones. También simplifican la interrogación y la presentación de la información. Un SGBD permite controlar el acceso a los datos, asegurar su integridad, gestionar el acceso concurrente a ellos, recuperar los datos tras un fallo del sistema y hacer copias de seguridad. Las bases de datos y los sistemas para su gestión son esenciales para cualquier área de negocio, y deben ser gestionados con esmero y calidad
Evolución De Los SGBD
La historia de las bases de datos inicia a mediados de los años cincuenta, en el momento en que comenzaron a introducirse los ordenadores para automatizar la gestión de las empresas, fundamentalmente con desarrollos en COBOL, y se han caracterizado por el uso de tecnologías orientadas a la estructuración de datos mediante modelos jerárquicos y Codasyl (p.ej. IMS de IBM; IDMS de Cullinet) de lógica procedimental, que obligan al programador a desplazarse registro a registro, hecho que implica una escasa flexibilidad.
En 1970 se propuso el modelo relacional, basado en los trabajos del Dr. Codd, básicamente el modelo matemático que dio fundamentos a la segunda generación de SGBD, caracterizada por una mayor independencia físico-lógica, dado que actúan sobre conjuntos de registros; entre ellas destacan ORACLE, DB2, INGRES, INFORMIX, SYBASE, etc. Codd propuso un modelo simple de datos en el que todos ellos se representarían en tablas constituidas por filas y columnas. A dichas tablas se les dio en nombre matemático de relaciones, denominándose así el sistema como relacional.
Codd también propuso dos lenguajes para manipular los datos en las tablas: álgebra y cálculo relacional, que soportan la manipulación de los datos sobre la base de operadores lógicos en lugar de los punteros físicos utilizados en los modelos jerárquicos y de red. El resultado fue la aparición de sistemas relacionales durante la última mitad de los setenta que soportaban lenguajes como el Structured Query Language (SQL), el Query Language (Quel) y el Query-by-Example(QBE): los trabajosde investigación que se realizaron durante la década de los ochenta se centraron en la optimización de consultas, lenguajes de alto nivel, teoría de la normalización, organizaciones físicas para el almacenamiento de las relaciones, algoritmos para la gestión de memorias intermedias (buffers), técnicas de indexación para un acceso asociativo más rápido (distintas variaciones de los árboles), sistemas distribuidos, diccionarios de datos, gestión de transacciones, etc. Estas investigaciones han tenido como consecuencia la elevada tasa de transacciones de muchos de los productos actuales que permiten asegurar entornos transaccionales en línea (OLTP) muy eficientes y seguros. También cabe recordar que durante la primera mitad de los ochenta se estandariza el lenguaje SQL (el SQUANSI se aprueba en 1986), ofreciendo, al cabo de poco tiempo, prácticamente todos los productos una interfaz SQL, aún los no relacionales (sistemas “renacidos”).
El enfoque relaciona1 permite a los programadores la manipulación de tuplas procedentes de distintos ficheros y tablas en una misma base de datos mediante consultas estructuradas, habilitando acciones múltiples sobre los registros. La aparición y estandarización de SQL, permitió una mayor integración, multiplicó las tareas asignadas a las bases de datos e implicó el desarrollo de sistemas de uso transparente, cuya facilidad de manejo derivó en una excepcional productividad e impresionante impacto económico.
La tercer generación de SGBD, tiene como principal característica la optimización relaciona1 de los sistemas en entornos multiusuario, la gestión de objetos que permite tipos de datos complejos (texto, imagen, audio...), el encapsulamiento de la semántica de datos que proporciona un soporte robusto para la recuperación automática de la información y mantenimiento de las restricciones de integridad entre datos.
Es posible clasificar los distintos sistemas como gestores de información “natural”. En la evolución de esta generación destacan dos indicadores: una arquitectura a tres niveles con descripción recursiva de datos (ANSI, ISO) como referencia; y el modelo relacional.
Funcionalidad de SGBD
Función de descripción o de definición. Esta función debe permitir al administrador de la base especificar los elementos de datos que la integran , su estructura, las relaciones que existen entre ellos, las reglas de integridad semántica, los controles a efectuar antes de autorizar el acceso a la base, etc. Esta función se lleva a cabo mediante el Lenguaje de Descripción o de Definición de Datos (LDD) propio de cada SGBD y debe suministrar los medios para definir las tres estructuras de datos – externa, lógica global e interna -, especificando las características de los datos a cada uno de estos niveles.
Función de manipulación. Permite a los usuarios de la Base buscar, añadir, suprimir o modificar los datos de la misma, siempre de acuerdo con las especificaciones y las normas de seguridad establecidas por el administrador. Esta función se realiza mediante el Lenguaje de Manipulación de Datos (LMD) que facilita los instrumentos necesarios para la realización de estas tareas.
Función de utilización. Reúne todas las interfaces que necesitan los diferentes usuarios para comunicarse con la base y proporciona un conjunto de procedimientos para el administrador entre los que se encuentra el Lenguaje de Control de Datos (LCD). Además, en la mayoría de los SGBD existentes en el mercado existen funciones de servicio, como cambiar la capacidad de los ficheros, obtener estadísticas de utilización, cargar archivos, etc., y otras relacionadas con la seguridad física - copias de seguridad, rearranque en caso de caída del sistema, etc. – y protección frente a accesos no autorizados.
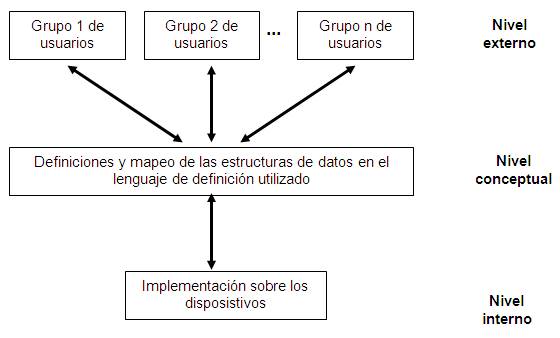
Arquitectura de los SGBD
Desde comienzos de los años setenta diversos grupos informáticos se han ocupado del tema de la estandarización de las bases de datos (ISO, INRIA, GESC, BSI, Codasyl, ANSI, etc) con el fin de conseguir que, una vez desarrollado un sistema e instrumentado en un determinado SGBD, el cambio de éste a otro producto comercial no implique tener que diseñar de nuevo la base de datos, ni tampoco que los programas que acceden a dicha base de datos tengan que ser reescritos. La estandarización ha de ofrecer también la oportunidad de adquirir distintos componentes de un SGBD (lenguajes, diccionarios, etc.) a diferentes suministradores.
La arquitectura a tres niveles (interno, conceptual y externo) definidos anteriormente, establecidos por el grupo ANSI/X3/SPARC marca la línea de investigación fundamental para la normalización y estandarización de los SGBD.
Esta arquitectura triesquemática de ANSI está parcialmente basada en el concepto de máquinas anidadas (llamadas de tipo cebolla). El flujo de datos pasa a través de las distintas capas que están separadas por interfaces que tienden a aislar los diversos componentes del sistema para conseguir el objetivo de independencia.
En las arquitecturas se distinguen dos partes:
Definición de la Base de Datos: La parte de definición se facilita por medio de una serie de funciones de programa e interfaces, que dan lugar a un conjunto de datos llamados metadatos (datos acerca de los datos) que se almacenan en el diccionario (catálogo o metabase en los sistemas relacionales), que es el eje principal de la arquitectura alrededor del cual giran los demás elementos.
Una base de datos se define especificando primeramente el esquema conceptual mediante un lenguaje de definición del esquema conceptual o una herramienta CASE integrada. Este esquema conceptual es compilado por el procesador del esquema conceptual y se almacena en el catálogo de datos.
El procesador del esquema conceptual muestra, por ejemplo, mediante menús, la información del esquema conceptual, mediante dicha información pueden definirse los esquemas externo e interno a través de distintas interfaces. Estos esquemas, claramente diferenciado, llevan a considerar la existencia de tres tipos de administraciones: Administración por parte de la Empresa, Administración de la Base de Datos y Administración de Aplicaciones
Manipulación de la Base de Datos: El usuario puede manipular (insertar, borrar, modificar y recuperar) los datos utilizando un interfaz que puede ser un lenguaje de manipulación de datos, por ejemplo SQL. Una petición de datos por parte del usuario se ejecuta por los transformadores externo /conceptual, conceptual /interno e interno/ almacenado que utilizan los metadatos devolviendo el resultado al usuario.
Estos transformadores constituyen la función de vinculación entre los distintos niveles (conceptual, interno y externo).
La arquitectura a tres niveles de ANSI responde por tanto positivamente a las exigencias de independencia, flexibilidad y capacidad de evolución propuestas en la estandarización.
Modelos de Datos
En una primera aproximación puede decirse que un Modelo de Datos (MD) es un conjunto de conceptos que permiten describir, a distintos niveles de abstracción, la estructura de una base de datos, a la que se denomina esquema. Según el nivel de abstracción de la arquitectura ANSI a tres niveles en el que se encuentre la estructura descrita, el modelo que permite que su descripción será un modelo externo, global o interno.
Los modelos externos permiten representar los datos que necesita cada usuario en particular con las estructuras propias del lenguaje de programación que va a emplear.
Los modelos globales ayudan a describir los datos para el conjunto de los usuarios de la Base de Datos.
Los modelos internos, llamados también modelos físicos, están orientados a la máquina, siendo sus elementos de descripción punteros, índices, agrupamientos, etc.
Lenguaje De Bases De Datos
En general, los usuarios informáticos, como el diseñador de la base, el administrador, analistas, programadores, etc., requerirán medios potentes y flexibles con los cuales consigan definir, administrar, extraer o manipular los datos de la base. Normalmente se apoyarán en un lenguaje de programación que están habituados a manejar (“Lenguaje Anfitrión”), para lo cual deberá permitir hacer llamadas desde un programa de aplicación al SGBD.
El conjunto de sentencias de manipulación del SGBD que pueden ser llamadas desde un lenguaje de programación permitiendo el acceso a la base de datos, se suele denominar sublenguaje de datos o también lenguaje huésped o lenguaje embebido.
Los SGBD admiten en general, varios lenguajes de tipo anfitrión para manipular datos (Cobol, Ensamblador, Fortran, PL/I, Basic, Pascal, C, etc.). Así mismo, la práctica totalidad de los SGBD admiten lenguajes de 4ª generación que permiten el acceso a la base de datos, mediante sentencias embebidas en dicho lenguaje y escritas en un lenguaje de datos como SQL.
El usuario final, por su parte, requerirá medios simples para comunicarse con la base, lo que puede conseguirse mediante un lenguaje de manipulación auto contenido, que tenga una sintaxis sencilla, pero potente como para soportar demandas de información muy variadas o por medio de tratamientos parametrizados que suelen presentarse al usuario en forma de menús.
La estructura y la sintaxis de estos tipos de lenguajes dependen de cada SGBD. Para modelo de datos en red, las normas Codasyl proponen especificaciones concretas de la sintaxis para los lenguajes de descripción y manipulación de los datos. Para modelos de datos relacionales el SQL es un estándar muy extendido que proporciona estas facilidades.
Lenguajes de Definición de Datos
Los instrumentos que permiten al administrador de la BD describir los datos con facilidad y precisión, especificando sus distintas estructuras es lo que se denomina Lenguaje de Definición de Datos (LDD). Suelen ser lenguajes auto contenido y no necesitan apoyarse en ningún lenguaje de programación. El SGBD deberá facilitar los medios para describir la estructura lógica global, para hacer las especificaciones relativas a la estructura interna y para declarar las estructuras externas que sean requeridas para el desarrollo de distintas aplicaciones.
Lenguajes de definición de la estructura lógica global
Desde el punto de vista lógico global el administrador debe disponer de un instrumento de descripción que permita asignar nombres a los campos, a los agregados de datos, a los registros, etc. estableciendo sus longitudes y sus características así como las relaciones entre estos elementos, especificar los identificadores e indicar restricciones semánticas que se han de aplicar a los diferentes objetos descritos.
Lenguajes de definición de la estructura lógica interna
En teoría, el propio SGBD debería conseguir automáticamente la optimización del almacenamiento y recuperación de los datos y encargarse, a partir de la estructura lógica global, de definir la estructura interna adecuada sin intervención del usuario (administrador).
Para ello, habría que suministrar al SGBD las informaciones precisas sobre volúmenes, crecimiento previsto, tipos de registros más accedidos, con indicaciones del número medio de accesos, relación entre actualizaciones y consultas, etc.
En la práctica, puede mejorarse sensiblemente la eficiencia si el administrador especifica características respecto a la estructura física, por lo que deberá disponer de un lenguaje de definición de la estructura interna o, simplemente, deberá dar valores a ciertos parámetros.
En muchos SGBD se suministra automáticamente por defecto una estructura interna, que es la que el sistema considera más adecuada para la estructura lógica global definida, aunque el administrador deberá ajustar posteriormente dicha estructura interna para conseguir una mayor eficiencia.
Lenguajes de definición de las estructuras externas
El SGBD debe poner a disposición de los usuarios los medios necesarios para recuperar o actualizar los datos contenidos en la base de datos, de acuerdo con la visión lógica o estructura externa (vista) que precise cada aplicación.
Al definir una estructura externa es preciso darle un nombre e indicar qué datos y qué interrelaciones de la estructura lógica global se encontrarán en la misma. Cuando se desee utilizar un esquema externo ya definido se podrá hacer referencia al mismo invocando su nombre desde el lenguaje de manipulación.
Lenguajes de manipulación de datos
Para cumplir los objetivos asignados a la función de manipulación debe disponerse de lenguajes que ofrezcan a los usuarios la posibilidad de referirse a determinados conjuntos de datos, que cumplan ciertas condiciones (criterio de selección) como que un atributo que tenga un determinado valor, o un conjunto de atributos y valores que satisfagan cierta expresión lógica. Además del criterio de selección, es preciso indicar la estructura externa que se desea actualizar o recuperar.
Que es un DBA
El Administrador De Bases De Datos (DBA), es el que administra las tecnoligias de la información y comunución.
Los administradores de bases de datos tienen competencias y capacidades en uno o más sistemas de gestión de bases de datos, algunos ejemplos: Microsoft SQL Server, IBM DB2, Oracle MySQL, Oracle database, IBM Informix y SQL Anywhere.
En la ingeniería estadística es la que trata la información para almacenarla, hacerla altamente explotable y altamente disponible. Además, vela por la eficacia técnológica del almacenamiento en el desempeño de investigaciones, buscando inferencias sólidas y compactas, para canalizar resultados manteniendo un equilibrio entre las ciencias involucradas y la propiamente enunciada
Porque las empresas optan por utilizar e implementar bases de datos
Las empresas utilizan las bases de datos para un mejor manejo de la información y una mejor organización de la misma, y pueden acceder mas facilmente a ella,y al implementarla tendra mas beneficios para ellas mismas.
Ventajas De las Bases De Datos
Independencia de los datos y los programas y procesos: Permite modificar los datos, excepto el código de aplicaciones.
Menor redundancia: es decir, no es necesario la repetición de datos. Solamente se indica la manera en la que se relacionan éstos.
Obtener más información de la misma cantidad de datos: La base de datos facilita al usuario obtener más información debido a la facilidad que provee esta estructura para proveer datos a los usuarios.
Integridad de los datos: lo que genera mayor dificultad de perder la información o de realizar incoherencias con los datos.
Mayor seguridad en los datos: Al permitir restringir el acceso a los usuarios, cada tipo de éstos tendrá la posibilidad de acceder a ciertos elementos.
Coherencia de los resultados: Al recolectar y almacenarse la información una sola vez, en los procedimientos se utilizan los mismos datos, razón por la que los resultados son coherentes.
Datos más documentados: Gracias a los metadatos que permiten detallar la información de la base de datos.
Acceso simultaneo a los datos: facilitando controlar el acceso de usuarios de manera concurrente.
Balance de Requerimientos Conflictivos: Para que la Base de Datos trabaje apropiadamente, necesita de una persona o grupo que se encargue de su funcionamiento. El título para esa posición es Administrador de Base de Datos y provee la ventaja de que Diseña el sistema tomando en mente la necesidad de cada departamento de la empresa. Por lo tanto se beneficia mayormente la empresa aunque algunos departamentos podrían tener leves desventajas. Tradicionalmente se diseñaba y programa según la necesidad de cada departamento por separado.
Reducción del espacio de almacenamiento: debido a una mejor estructuración de los datos.
Acceso a los datos más eficiente: La organización de los datos produce un resultado más óptimo en rendimiento. Igualmente, en el caso de empresas, usuarios de distintas oficinas pueden compartir datos si están autorizados.
Reducción del espacio de almacenamiento: gracias a una mejor estructuración de los datos.
Se refuerza la estandarización: Debido a que es más fácil estandarizar procesos, formas, nombres de datos, formas, etc.
Flexibilidad y rapidez al obtener datos El usuario puede obtener información de la Base de Datos con escribir breves oraciones. Esto evita el antiguo proceso de llenar una petición al Centro de Cómputos para poder obtener un informe.
Aumenta la productividad de los programadores: debido a que los programadores no se tienen que preocupar por la organización de los datos ni de su validación, se pueden concentrar en resolver otros problemas inmediatos, mejorando de ese modo su productividad.
Desventajas De Las Bases de Datos
Ausencia de estándares reales: lo cual significa una excesiva dependencia a los sistemas comerciales del mercado. Sin embargo, actualmente un gran sector de la tecnología esta aceptado como estándar de hecho.
Requiere personal calificado: debido a la dificultad del manejo de este tipo de sistemas. Esto requiere que los programadores y los analistas deben tomar cursos que los adiestren para poder comprender las capacidades y limitaciones de las Bases de Datos.
Instalación costosa: ya que el control y administración de bases de datos requiere de un software y hardware de elevado coste. Además de la adquisición y mantenimiento del Sistema Gestor de Datos (SGBD).
Falta de rentabilidad a corto plazo: debido al coste de equipos y de personal, al igual del tiempo que tarda en estar operativa.
Tamaño: El Sistema de Manejo de Base de Datos (DBMS) requiere de mucho espacio en disco duro y también requiere de mucha memoria principal (RAM) para poder correr adecuadamente.
Requerimientos adicionales de Equipo: El adquirir un producto de Base de Datos, requiere a su vez adquirir equipo adicional para poder correr ese producto como por ejemplo, servidores, memoria, discos duros, entre otros. Si se pretende correr la Base de Datos con el mínimo de requerimientos, esta posiblemente se degrada.
Mapa conceptual
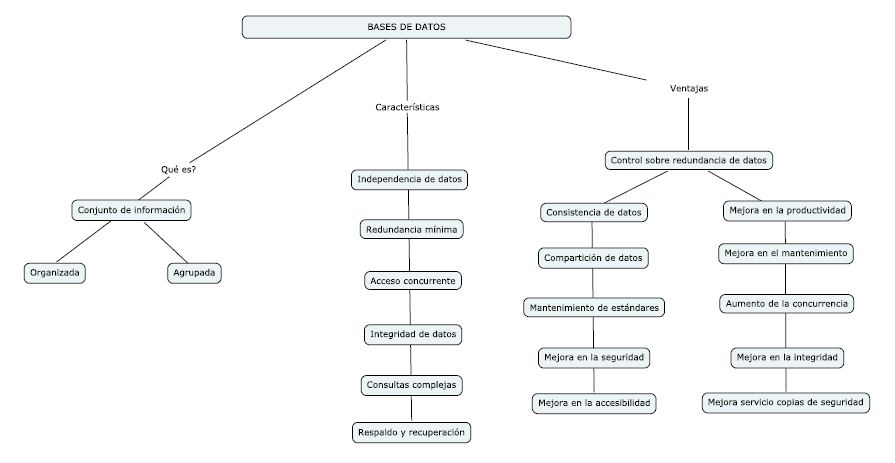
Base de Datos: Una base de datos es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso.
Base de Datos Relacional: Es una base de datos que cumple con el modelo relacional, el cual es el modelo más utilizado en la actualidad para implementar bases de datos ya planificadas. Permiten establecer interconexiones (relaciones) entre los datos (que están guardados en tablas), y a través de dichas conexiones relacionar los datos de ambas tablas, de ahí proviene su nombre: Modelo Relacional
Dato: En programación, un dato es la expresión general que describe las características de las entidades sobre las cuales opera un algoritmo. En Estructura de datos, es la parte mínima de la información
Tupla: Es una secuencia ordenada de objetos, es una lista con un número limitado de objetos (una secuencia infinita se denomina en matemática, aunque hay autores que consideran el término tupla para denominar no solo listas finitas). Las tuplas se emplean para describir objetos matemáticos que tienen estructura, es decir que son capaces de ser descompuestos en un cierto número de componentes
Atributo: En Informática, un atributo es una especificación que define una propiedad de un objeto, elemento o archivo. También puede referirse o establecer el valor específico para una instancia determinada de los mismos.
Registro: Un registro, en programación, es como un tipo de dato estructurado formado por la unión de varios elementos bajo una misma estructura. Estos elementos pueden ser, o bien datos elementales (entero, real, carácter,...), o bien otras estructuras de datos. A cada uno de esos elementos se le llama campo.
Tabla: En la base de datos, se refiere al tipo de modelado de datos, donde se guardan los datos recogidos por un programa. Su estructura general se asemeja a la vista general de un programa de hoja de cálculo, y se utiliza para organizar y presentar información.
Archivo: Un archivo o fichero informático es un conjunto de bits que son almacenados en un dispositivo. Un archivo es identificado por un nombre y la descripción de la carpeta. A los archivos informáticos se les llama así porque son los equivalentes digitales de los archivos escritos en libros, tarjetas, libretas, etc.
Dominio: Es un conjunto de ordenadores conectados en una red se le confía la administración a un equipo para que pueda administra los equipos que estén conectados a dicha red.
Clave: Es una pieza de información que controla la operación de un algoritmo. Habitualmente, esta información es una secuencia de números o letras mediante la cual se especifica la transformación del texto plano en texto cifrado, o viceversa. En sistemas informáticos, la clave sirve para verificar que alguien está autorizado para acceder a un servicio o un sistema.
Llave Primaria: En el diseño de bases de datos relacionales, se llama clave primaria a un campo o a una combinación de campos que identifica de forma única a cada fila de una tabla. Una clave primaria comprende de esta manera una columna o conjunto de columnas. No puede haber dos filas en una tabla que tengan la misma clave primaria.
Llave Foránea: En el contexto de bases de datos relacionales, una clave foránea o clave ajena (o Foreign Key FK) es una limitación referencial entre dos tablas. La clave foránea identifica una columna o grupo de columnas en una tabla
Cardinalidad: El cardinal indica el número o cantidad de elementos de un conjunto, sea esta cantidad finita o infinita. Los números cardinales constituyen una generalización interesante del concepto de número natural, permitiendo comparar la cantidad de elementos de conjuntos infinitos
Relación: Es aquello que se usa para verificar datos y mirar si coinciden en algo, a eso se le puede llamar relación.
Usuario: Es una persona que interactúa en las redes digitales